Firecrawl
Crawl and convert web pages into clean markdown for LLM consumption. Built for RAG and agent data pipelines.
Firecrawl is a web scraping and crawling API built specifically for AI applications. It converts any website into clean, structured data — markdown, JSON, or screenshots — ready for use in RAG pipelines, LLM context windows, and autonomous agents. The tool is open source and trusted by over 80,000 companies including Shopify, Zapier, Canva, and Apple.
At its core, Firecrawl solves a problem that most developers hit quickly when building AI applications: the web is messy, JavaScript-heavy, and hostile to naive scrapers. Firecrawl handles all of that behind a simple API. It claims to cover 96% of the web, including JS-rendered pages, with a P95 latency of 3.4 seconds across millions of pages — benchmarks it publishes openly for comparison against tools like Puppeteer and raw cURL.
The API surface covers four main operations. Scrape fetches a single page and returns it as markdown, JSON, or a screenshot. Search queries the web and returns full page content from results — essentially a search engine with built-in content extraction. Map discovers all URLs across a site, useful for understanding site structure before a crawl. Crawl traverses an entire site and returns data from every page.
For AI agent developers, Firecrawl offers two integration paths. The first is a CLI tool (firecrawl-cli) that gives agents direct access to web data. The second is an MCP (Model Context Protocol) server (firecrawl-mcp) that connects any MCP-compatible client — including Claude, Cursor, and similar tools — to live web data in seconds via a simple JSON config block.
Compared to alternatives, Firecrawl occupies a distinct position. Tools like BeautifulSoup or Scrapy are lower-level and require significant engineering to handle JS rendering, rate limiting, and output normalization. Puppeteer and Playwright are browser automation tools that can scrape but aren't optimized for LLM output formats. Apify and Diffbot are commercial competitors with broader automation platforms but less focus on the AI/LLM use case. Firecrawl is narrowly focused on the AI data pipeline problem, which makes it a natural fit for teams building RAG systems or agent workflows without wanting to maintain their own scraping infrastructure.
The open source nature of the project means teams can self-host if needed, though the managed API is the primary offering. SDKs are available for Python and Node.js, with cURL support for any environment.
Key Features
- Scrape: Converts any web page to markdown, JSON, or screenshot with a single API call
- Crawl: Traverses entire websites and returns structured data from every discovered page
- Search: Queries the web and returns full page content from results, not just links
- Map: Discovers all URLs on a site for structural analysis before crawling
- Interact (new): Scrapes a page then interacts with it using AI prompts or code
- MCP server: Connects any MCP-compatible AI client to live web data via a JSON config block
- CLI tool: Gives AI agents a full web data toolkit for searching, scraping, and interacting
- JS rendering support: Handles JavaScript-heavy pages, covering 96% of the web without proxies
Pros & Cons
Pros
- Purpose-built for LLM and AI pipelines — output formats (markdown, JSON) are ready to use without post-processing
- Covers JS-heavy pages out of the box, handling a common failure point for simpler scrapers
- MCP server support makes it trivially easy to wire into agent frameworks and AI IDEs
- Open source with self-hosting option for teams with data sovereignty requirements
- Trusted at scale by major companies, with published performance benchmarks
Cons
- Managed API means ongoing cost and external dependency for production workloads
- Latency of ~3.4s at P95 may be too slow for use cases requiring near-instant responses
- Crawling large sites can be expensive in terms of API credits
- Less suitable for non-AI scraping use cases where raw HTML or full browser control is needed
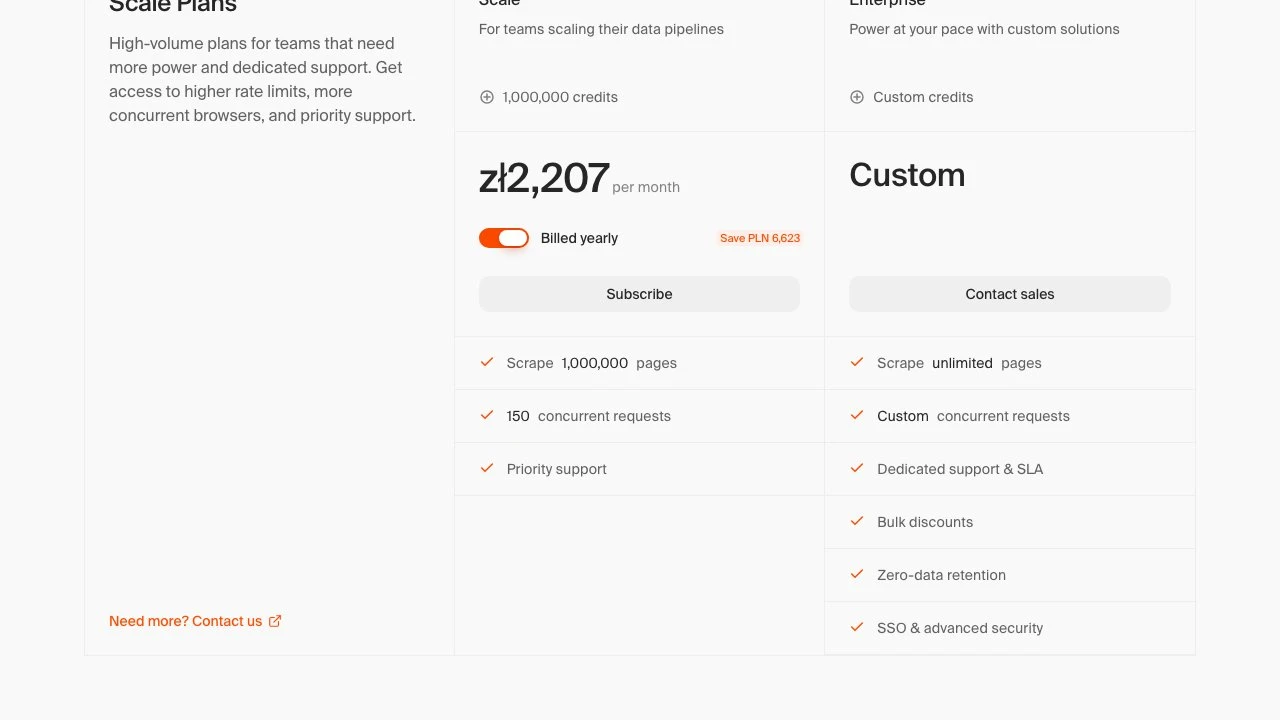
Pricing
Firecrawl offers an annually billed plan with two months free. Specific tier pricing and credit limits are available on the pricing page at firecrawl.dev/pricing.
Who Is This For?
Firecrawl is best suited for developers and AI engineers building RAG pipelines, autonomous agents, or any application that needs to ingest live web content. It is particularly well matched for teams who want production-grade web data without maintaining their own scraping infrastructure, and for agent developers who need MCP-compatible web access out of the box.
Tags:

Similar to Firecrawl