Portkey
AI gateway with load balancing, fallbacks, caching, and observability for LLM API calls.
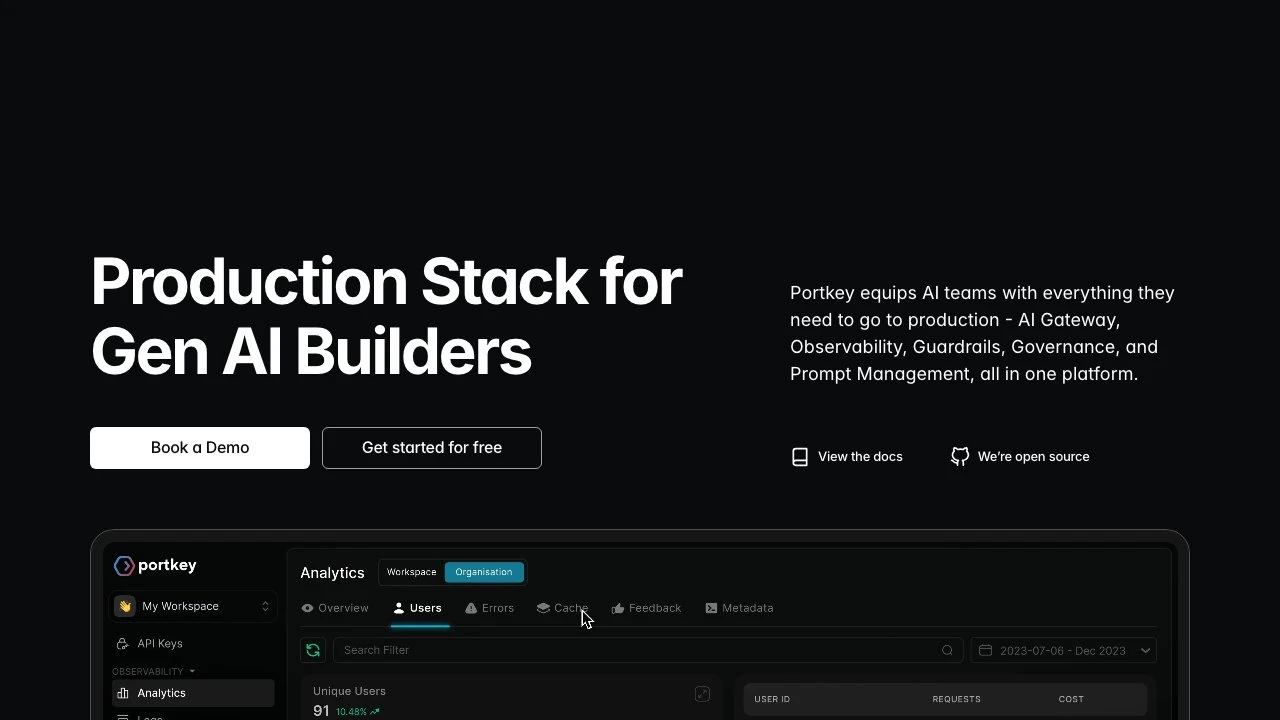
Portkey is an AI gateway platform designed to bring production-grade reliability, observability, and governance to teams building with large language models. At its core, Portkey sits between an application and any number of LLM providers, acting as a unified control plane for all AI API traffic.
The platform provides access to over 1,600 LLMs through a single, OpenAI-compatible API. This means teams can switch between providers — OpenAI, Anthropic, Azure, and hundreds of others — without rewriting integration code. The integration footprint is minimal: Portkey advertises a three-line code change and SDK support for Node.js, Python, and direct OpenAI SDK compatibility, making it straightforward to adopt without rearchitecting an existing stack.
Beyond routing, Portkey handles the operational concerns that emerge when LLMs move from prototype to production: load balancing across providers, automatic fallbacks when a model is unavailable or rate-limited, semantic caching to avoid redundant API calls, and real-time cost and usage monitoring. The caching layer in particular has drawn attention from teams running high-volume workloads — one engineering team reported saving thousands of dollars on repeated test runs.
The observability layer surfaces per-request logs, token usage, latency, and cost attribution at the user and team level. This is a meaningful differentiator compared to building dashboards in-house or relying on provider-level analytics, which typically lack cross-provider aggregation and user-level breakdowns.
Portkey also includes a guardrails system with PII redaction, which strips sensitive data from requests before they reach the LLM provider. Combined with role-based access control (RBAC), budget limits, and workspace-level isolation, the platform addresses governance requirements that become critical for enterprise teams managing multiple internal users or client workloads.
A prompt management system allows teams to version and manage prompts outside of application code, reducing the friction of iterating on prompts in production environments. There is also support for production-ready agent workflows and an MCP (Model Context Protocol) gateway for teams using MCP-based tooling, centralizing authentication and observability for MCP servers.
Compared to alternatives like LiteLLM or AWS Bedrock's native routing, Portkey offers a more complete out-of-the-box platform — LiteLLM is open-source and flexible but requires more self-managed infrastructure, while Bedrock is limited to AWS-hosted models. Portkey occupies a middle ground: open-source core, with a managed SaaS control plane and an option to run the gateway in a private network for organizations with data residency requirements.
The platform reports processing trillions of tokens daily and serving over 3,000 GenAI teams, positioning it as an established choice for teams that need reliability and visibility without building bespoke infrastructure.
Key Features
- Unified API access to 1,600+ LLMs across providers with OpenAI-compatible interface
- Automatic load balancing and provider fallbacks to maintain uptime under rate limits or outages
- Semantic caching to reduce redundant LLM calls and lower API costs
- Real-time observability dashboard with per-request logs, token usage, latency, and cost attribution
- Guardrails with automatic PII redaction before requests reach the LLM
- Role-based access control (RBAC) and budget limits for multi-team governance
- Prompt management system for versioning and managing prompts outside application code
- MCP Gateway for centralized authentication and observability of Model Context Protocol servers
Pros & Cons
Pros
- Minimal integration effort — drop-in compatible with existing OpenAI SDK usage
- Broad provider coverage (1,600+ LLMs) reduces vendor lock-in
- Caching and fallback mechanisms directly reduce cost and improve reliability without custom code
- Cross-provider observability and user-level cost attribution in a single dashboard
- Supports hybrid deployment with gateway running in a private network and control plane in SaaS
Cons
- Adds a network hop to every LLM request, which may introduce latency in latency-sensitive applications
- Full feature set (governance, advanced guardrails, multi-team RBAC) may be more than small teams need
- Dependence on a third-party control plane raises data routing considerations for regulated industries
- Pricing for higher-volume or enterprise tiers is not publicly detailed on the website
Pricing
Portkey offers a free tier to get started. Paid plans include a referenced tier at $59.99 for 500,000 units. Visit the official website for current pricing details on enterprise and higher-volume plans.
Who Is This For?
Portkey is best suited for engineering teams and AI-focused companies that are moving LLM-based applications from prototype into production and need reliability, cost control, and visibility across multiple providers. It is particularly well-matched for organizations managing multiple internal teams or client workloads that require governance features like RBAC, budget enforcement, and audit-ready logging.

Similar to Portkey