Turbopuffer
High-performance serverless vector database. Object storage-backed for cost efficiency at scale.
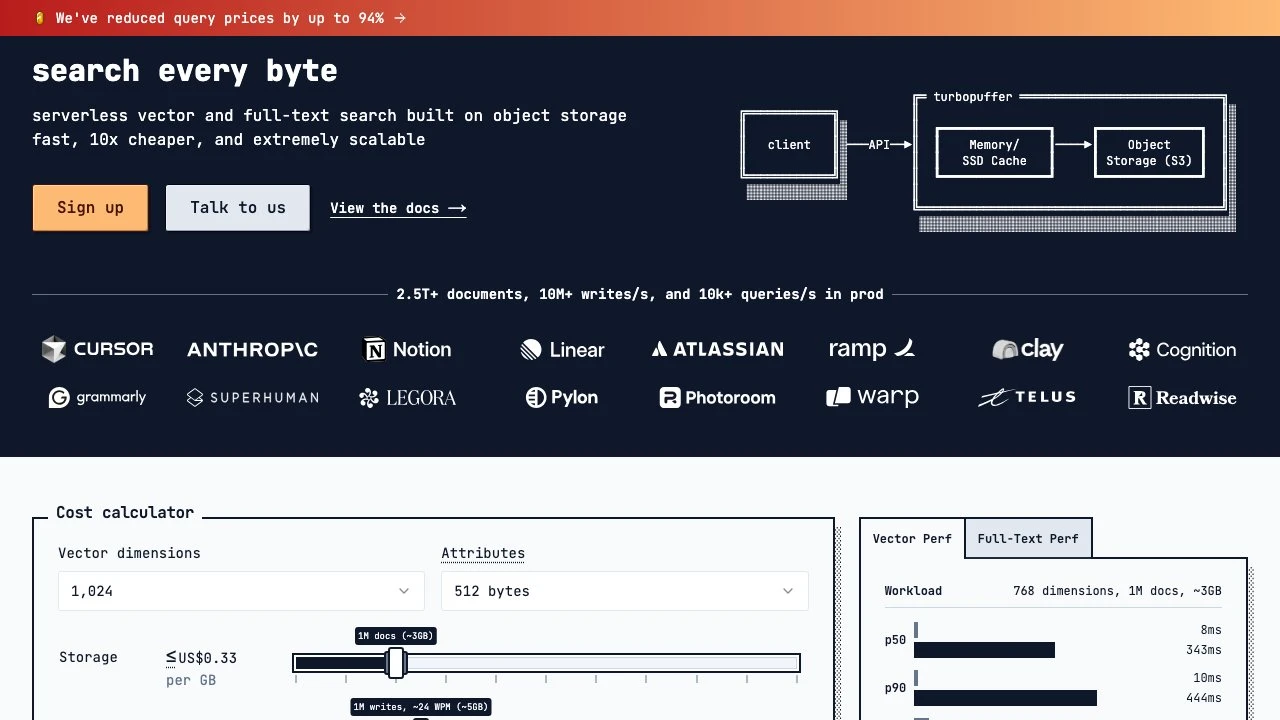
Turbopuffer is a serverless vector and full-text search database built on object storage (S3-compatible backends). Unlike traditional vector databases that rely on in-memory indexes or dedicated compute clusters, turbopuffer stores data in object storage and uses a Memory/SSD cache layer to serve queries — a architecture that significantly reduces infrastructure costs while maintaining low-latency performance.
At its core, turbopuffer is designed for AI applications requiring similarity search at scale: RAG pipelines, semantic search, recommendation engines, and any workload that needs to match embeddings or text across large document corpora. The system handles both vector search (ANN — approximate nearest neighbor) and full-text search, with hybrid search combining both modes available for use cases where keyword and semantic relevance need to be weighted together.
The serverless model means there are no clusters to provision or size. Namespaces (the unit of organization) scale independently and automatically. Turbopuffer reports handling 2.5T+ documents, 10M+ writes per second, and 10k+ queries per second across its production deployments, with customers including Cursor, Notion, Linear, Anthropic, Grammarly, Atlassian, and Ramp.
Performance benchmarks published on the site show p50 query latency of 8ms for vector search on a warm namespace (768 dimensions, 1M documents). Cold namespace latency is higher, reflecting the cache-miss penalty inherent to the object-storage architecture — a trade-off that matters for workloads with infrequent access patterns but is largely irrelevant for steady, high-traffic namespaces.
Compared to alternatives like Pinecone, Weaviate, or Qdrant, turbopuffer's primary differentiator is cost. The site claims up to 10x cheaper than alternatives, backed by a public cost calculator and a documented pricing reduction of up to 94% on queries. This cost profile makes it particularly compelling for applications with large document volumes or high write throughput where traditional managed vector databases become expensive to operate.
The API surface is straightforward: clients write documents with vector and attribute payloads to named namespaces and query them with vector similarity, full-text, or hybrid modes, with optional metadata filters. SDKs and documentation are available, and the system is accessible via HTTP API, making it usable from any language or runtime.
For teams building AI products that need to search across billions of documents without managing infrastructure or absorbing the cost structure of always-on compute clusters, turbopuffer occupies a distinct and well-defined position in the vector database landscape.
Key Features
- Serverless architecture backed by object storage (S3), with Memory/SSD caching for low-latency query serving
- Vector search (ANN) with reported 90–100% recall@10 and sub-10ms p50 latency on warm namespaces
- Full-text search and hybrid search combining vector and keyword relevance
- Metadata filtering on document attributes during query execution
- Scales to 500M+ documents per namespace and unlimited namespaces globally
- Write throughput up to 10k writes/s per namespace, with unlimited global throughput
- Cost calculator and transparent, usage-based pricing with no idle cluster costs
- Production-tested at 2.5T+ documents across customers including Cursor, Notion, Linear, and Anthropic
Pros & Cons
Pros
- Significantly lower cost than traditional managed vector databases, with up to 10x savings reported by customers
- No infrastructure to provision or manage — namespaces scale automatically
- Supports both vector and full-text search in a single system, reducing the need for separate search infrastructure
- Proven at extreme scale in production (2.5T+ documents, 10M+ writes/s)
- Transparent pricing with a public cost calculator
Cons
- Cold namespace queries carry higher latency due to the object-storage cache-miss penalty — not ideal for infrequently accessed namespaces requiring consistent low latency
- Minimum plan cost of $64/month may be a consideration for very small or experimental workloads
- Per-namespace document limit of 500M @ 2TB, which may require sharding strategies at the largest scales
- Relatively newer entrant compared to incumbents like Pinecone or Weaviate, with a smaller ecosystem of third-party integrations
Pricing
Turbopuffer uses usage-based pricing with charges for storage, writes, and queries. A minimum of $64/month applies to the launch plan. A public cost calculator is available on the pricing page to estimate costs based on document count, vector dimensions, attribute size, and query volume.
Who Is This For?
Turbopuffer is best suited for engineering teams building AI applications — particularly RAG pipelines, semantic search, and recommendation systems — that need to operate at scale without the cost overhead of always-on managed vector databases. It is a strong fit for products with large or growing document corpora where storage and query costs at competitors become a constraint, and for teams that want a single system handling both vector and full-text search.

Similar to Turbopuffer